We present Specialist Diffusion, a style specific personalized text-to-image model. It is plug-and-play to existing diffusion models and other personalization techniques. It outperform the latest few-shot personalization alternatives of diffusion models such as Textual Inversion and DreamBooth, in terms of learning highly sophisticated styles with ultra-sample-efficient tuning.

Samples generated by our models fine-tuned on the three datasets. The left column shows the dataset on which the model is trained on, and the top row shows the text prompt used to generate the image.
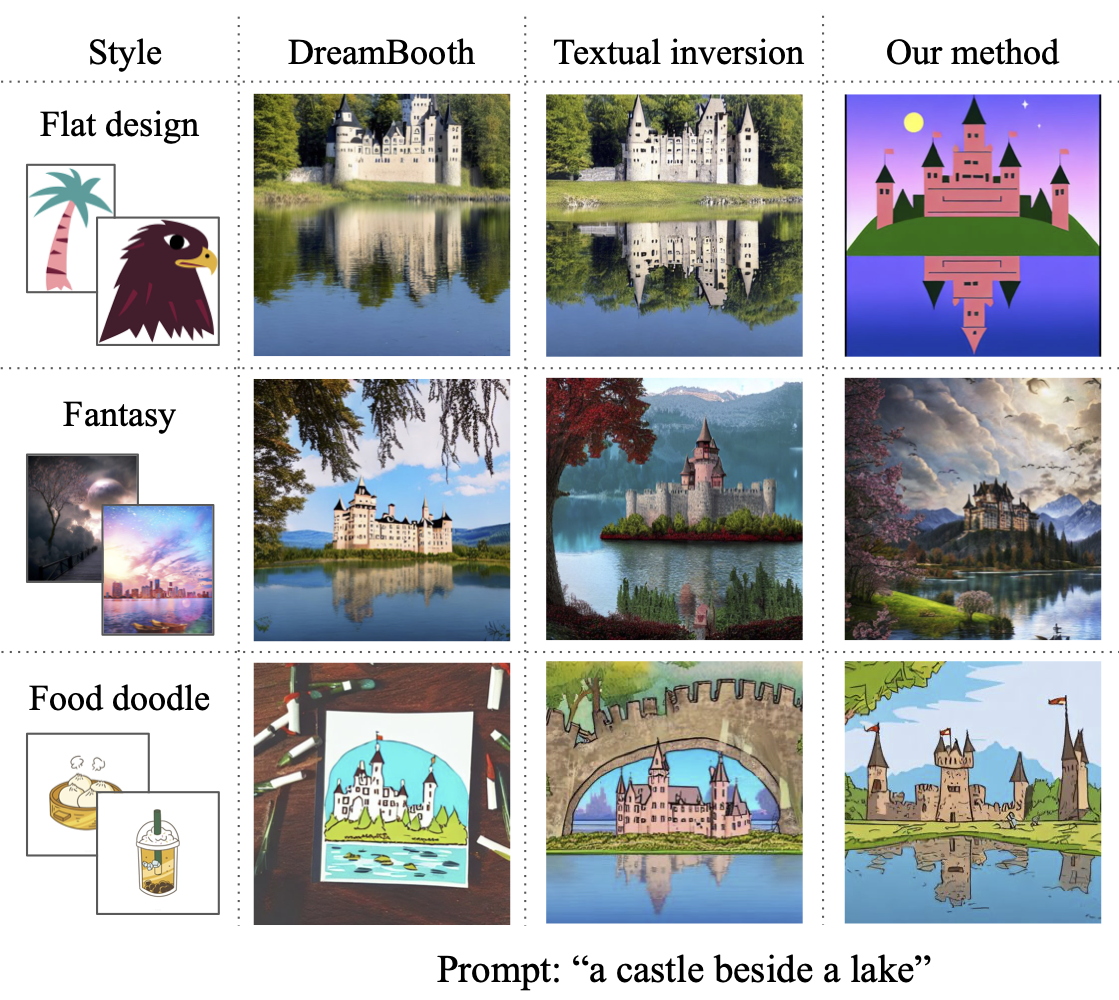
Comparison of fine-tuning the Stable Diffusion model. Three rows represent three different, rare styles models personalization, using only a handful of samples (even less than 10). All examples are generated using the same text prompt. Object specific DreamBooth performs poorly when being applied to capturing styles. Textual Inversion achieves neat performance on some styles, but fails on more unusual styles such as “Flat design”. Specialist Diffusion (rightmost) succeeds to capture those highly unusual, specialized, and sophisticated styles via few-shot tuning
Abstract
Diffusion models have demonstrated impressive capability of text-conditioned image synthesis, and broader application horizons are emerging by personalizing those pretrained diffusion models toward generating some specialized target object or style. In this paper, we aim to learn an unseen style by simply fine-tuning a pre-trained diffusion model with a handful of images (e.g., less than 10), so that the fine-tuned model can generate high-quality images of arbitrary objects in this style. Such extremely lowshot fine-tuning is accomplished by a novel toolkit of finetuning techniques, including text-to-image customized data augmentations, a content loss to facilitate content-style disentanglement, and sparse updating that focuses on only a few time steps. Our framework, dubbed Specialist Diffusion, is plug-and-play to existing diffusion model backbones and other personalization techniques. We demonstrate it to outperform the latest few-shot personalization alternatives of diffusion models such as Textual Inversion and DreamBooth, in terms of learning highly sophisticated styles with ultra-sample-efficient tuning. We further show that Specialist Diffusion can be integrated on top of Textual Inversion to boost performance further, even on highly unusual styles.
Method
Our framework carries a novel toolkit of fine-tuning techniques, including text-to-image (1) Advanced Data Augmentations, a (2) Content Loss to facilitate content-style disentanglement, and (3) Sparsely Updating time steps.
Advanced Augmentation
Illustration
Examples
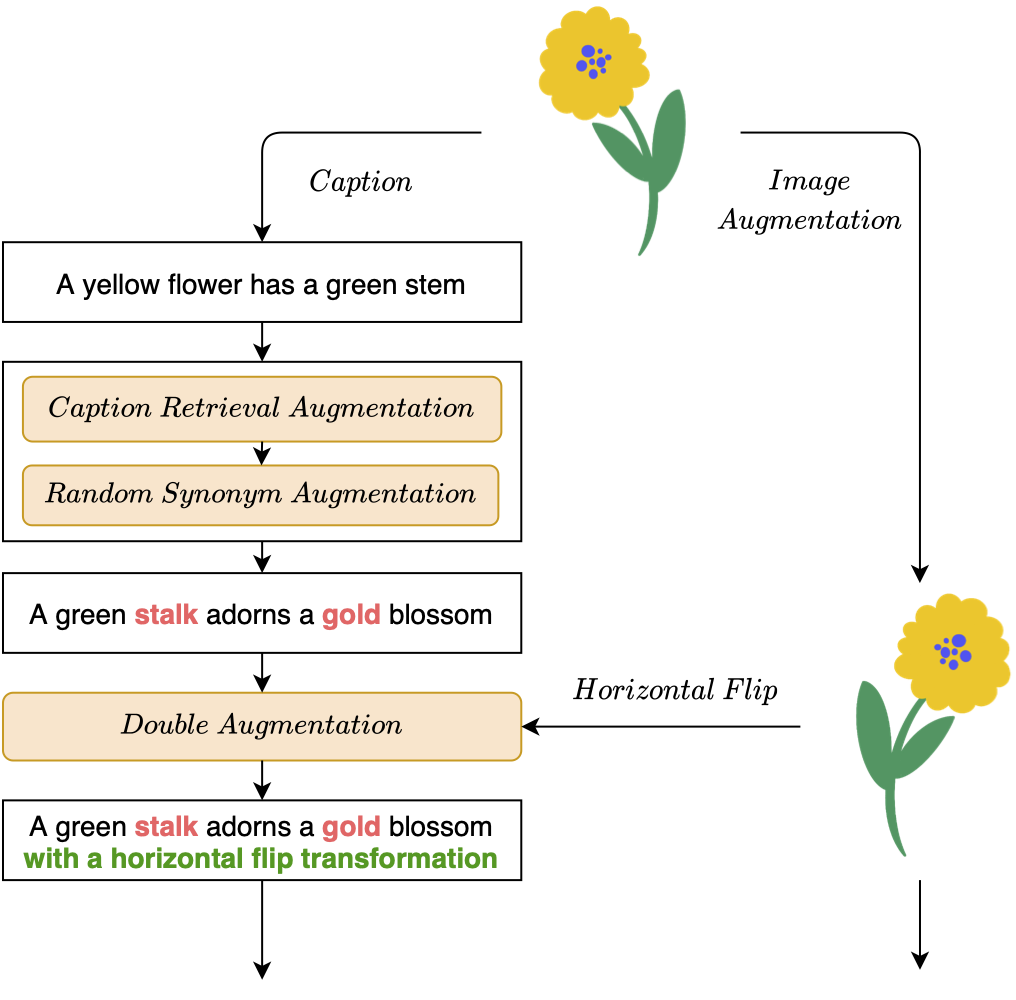
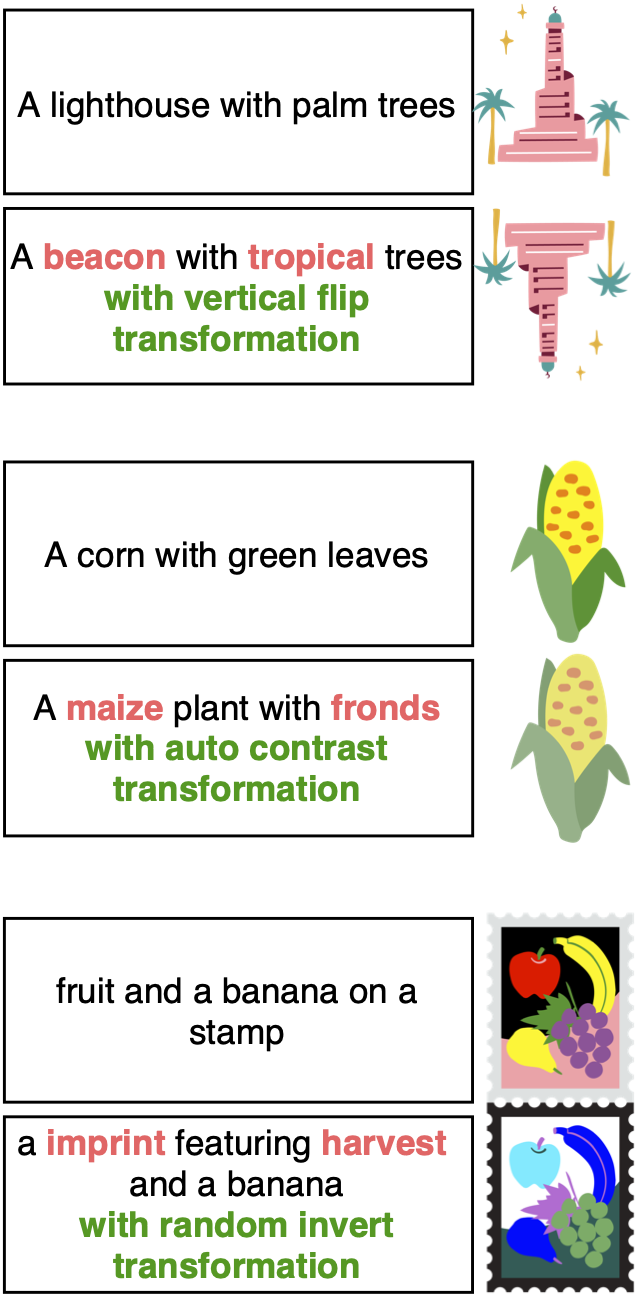
Overview of our customized data augmentation flow consisting Image Augmentation and three level of Caption Augmentation: 1) Caption Retrieval Augmentation, 2) Synonym Augmentation, and 3) Doubled Augmentation.
Content loss
Additional content loss is introduced to disentangle the knowledge of content (inherited from pretrained model) and style (learned from few-shot examples), and help preserve the model's ability to understand the semantics of the prompts.
\(arg\,min_{w\in w^{+}} D_{CLIP}(G(w), t) + R\)
Where \(G\) is an image generation network with \(w\) parameters, \(t\) denotes to the text prompt, \(D_{CLIP}\) is the cosine distance between CLIP embeddings of images and prompts, and \(R\) denotes other regularization terms.
Results

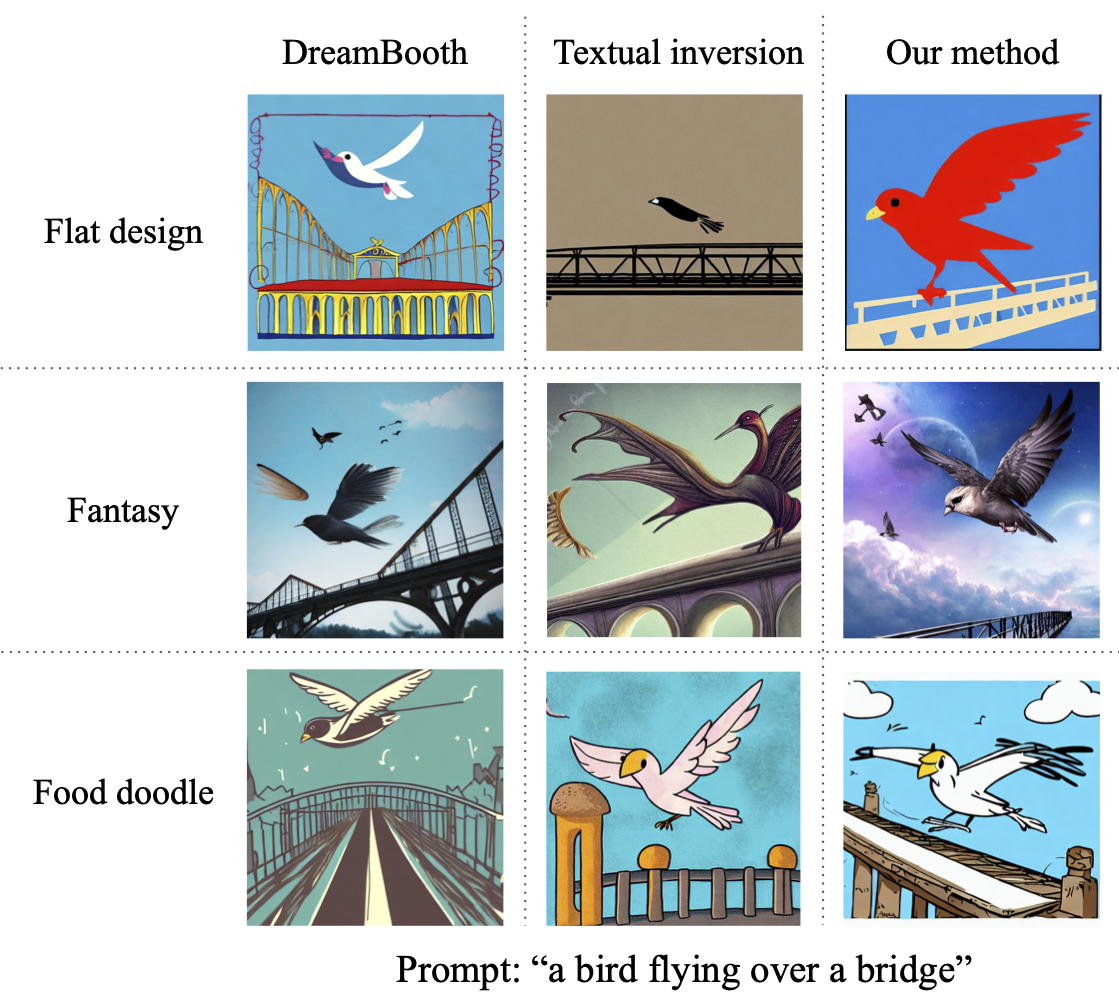
Continued comparison of our model and other SOTA methods. Random seed is fixed for generation in this figure.
Plug-and-Play

Combination of our model and Textual Inversion. Text prompts used for generation are listed top, styles of the respective datasets are listed under, and the methods for training the models are listed left. By integrating Textual Inversion with our model, the results capture even richer details without losing the style.
Ablation Study

Ablation study of the method. Text prompts for each group: (1)“a young brown woman walking her dog in a park at night with a full moon”; (2) “a castle beside a lake”. Methods for each group: (a) Stable Diffusion; (b) fined-tuned model by our full method; (c) our method w/o caption-retrieval augmentation; (d) our method w/o synonym and caption retrieval augmentations; (e) our method w/o content loss; (f) our method w/o sparse updating
User Study
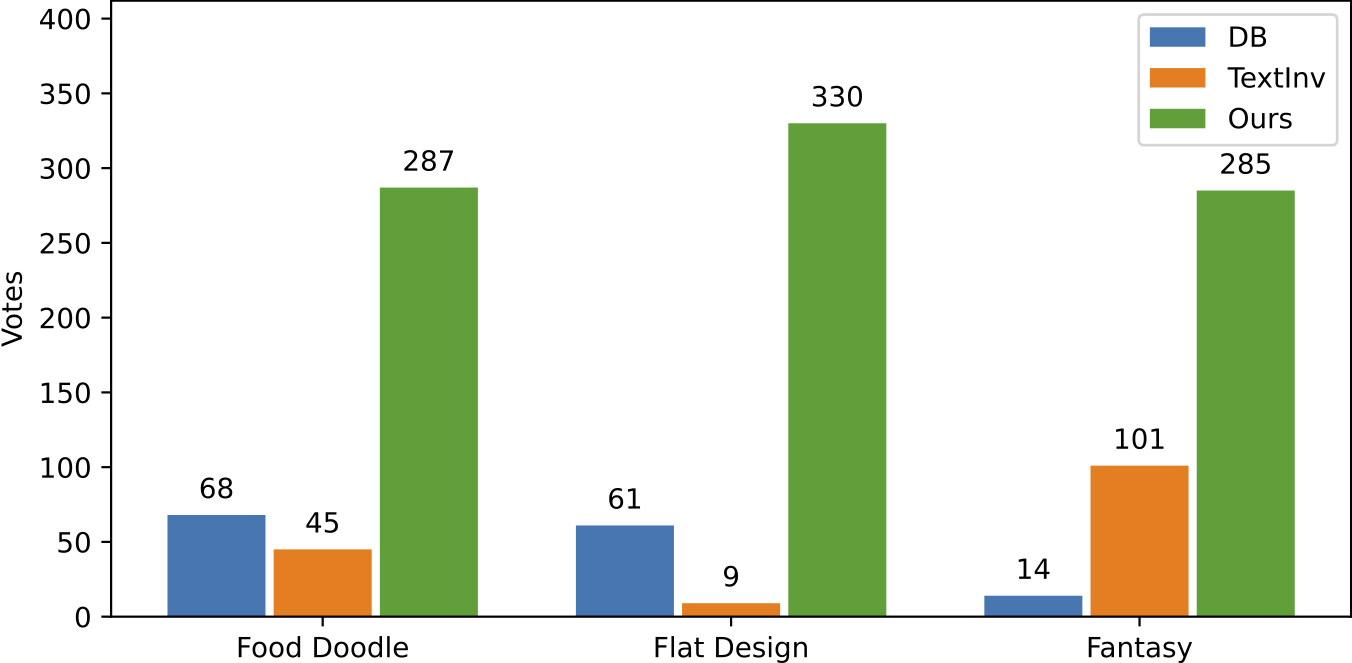
User study with the question: “which one of the three generated images aligns best with the reference image in style?”
BibTeX
If you find our work useful, please cite our paper:
@article{Specialist-Diffusion,
author = {Lu, Haoming and Tunanyan, Hazarapet and Wang, Kai and Navasardyan, Shant and Wang, Zhangyang and Shi, Humphrey},
title = {Specialist Diffusion: Plug-and-Play Sample-Efficient Fine-Tuning of Text-to-Image Diffusion Models to Learn Any Unseen Style},
journal = {CVPR},
year = {2023},
}